
Assessing Risk in Cybersecurity: How Sound Data Science Can Raise the Bar

Cybersecurity is a data-driven practice. Protective and responsive decisions are made on the basis of observations of user and system behavior. Artificial intelligence (AI) is used to learn good from bad and thresholds are set to trigger alerts or responses. However, cybersecurity is not currently a data science-driven practice, and the frustratingly slow progress in the development of cybersecurity technology reflects this deficiency.
Current cybersecurity solutions are fraught with challenges born from a lack of understanding of basic statistics. Operators are bombarded with too many false positives. Automated systems cannot attain a trustworthy level of accuracy. False positives must undergo further human or machine analysis (or, more likely, all alerts are ignored because there are just too many). Users of automated systems have to adopt a human-in-the-loop policy.
Enterprise users are forced to develop heuristic practices to overcome these shortfalls. These ad hoc strategies make real-time response impossible, so damage is done.
However, all is not lost. If greater data science savvy is brought to bear at the system design stage, rather than not at all or after the fact, these challenges can be overcome. The data scientist can apply expertise to assure data techniques are robust and pragmatic from the start, rather than to clean up spurious results. They can provide appropriate thresholds and other parameters. In short, they can make cyber analysis more scientific and presumably more effective.
Cybersecurity practitioners also often lack an understanding of the difference between risk and threat. Steeped in the cowboy crime-stopper mindset, they remain focused on eliminating all threats—but not all threats lead to risks that require action. Here again, a more scientific understanding of the situation can lead to more effective results-based, rather than threat-based, solutions.
The third way in which a data scientific approach can approve cyber analytics is by assuring the notion of adversarial behavior is properly introduced into analytic models. Most classification and learning models consider behavior as motiveless and treat data as random. However, cyber is an adversarial domain and the interactions among datum are influenced by the motives of the attacker and, to a lesser extent, of the defender. The predictive power of models can be greatly improved if the adversarial nature of the domain is correctly reflected in the model.
Elementary statistics courses teach that the ability of an algorithm to tell true from false is directly related to the distance between the two distributions. If bad cyber behaviors were red on the graph in Figure 1 and good cyber behaviors were aqua, it would be straightforward to design an algorithm that can identify the bad behaviors with few false positives. If, however, bad behaviors were red and good behaviors were green, it would be very difficult to do so. And unfortunately, overlapping distributions are common in cyber analysis.
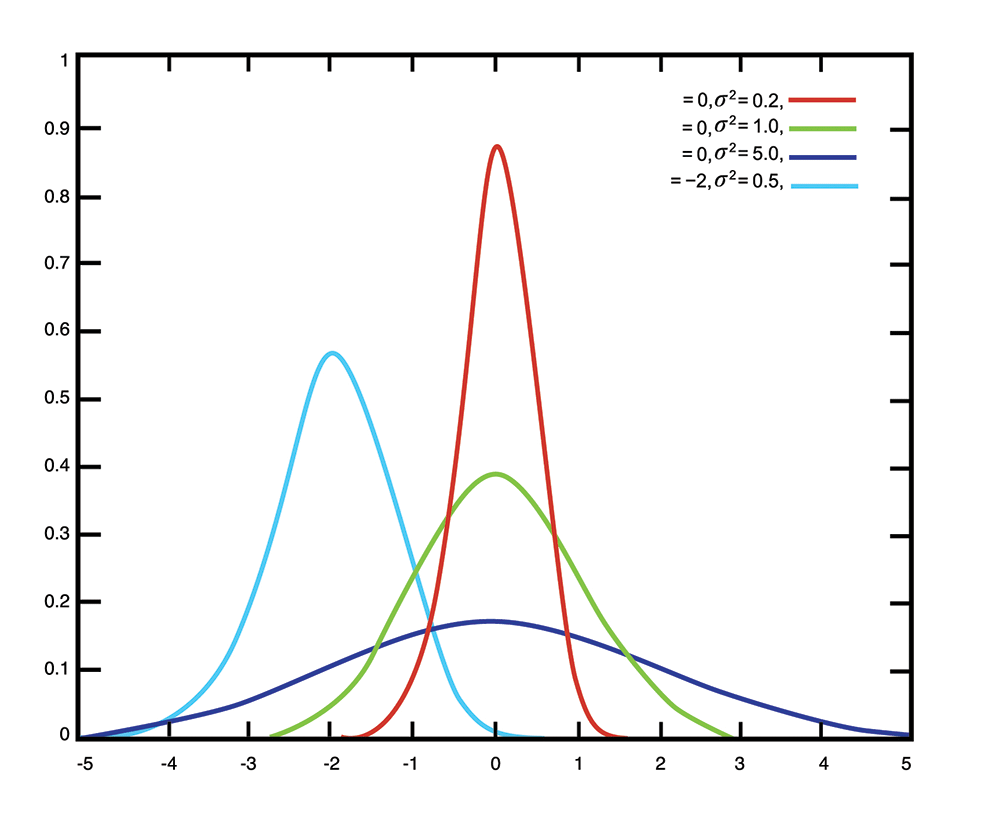
Figure 1: Several unimodal distributions on same graph.
Image credit: Grendelkhan | Wikimedia commons.
Without a context, few cyber behaviors are inherently good or bad. Consider ransomware—clearly a bad behavior. Its signature behavior is encrypting large numbers of files, but there are a number of valid use cases for doing that. When an employee resigns, it might be company policy to encrypt their files to ensure they have no further access. Perhaps you are traveling with your laptop and decided to encrypt your files in case your device is lost or stolen. Bulk encryption, in itself, is not a bad behavior—bulk encryption by an unauthorized user is.
If you set up a test to simply look for bulk encryption, basic statistics tells you that you will have poor results because there will be no separation between the good and bad distributions. Obviously, this example is oversimplified and ideally, no one is selling ransomware protection that only looks for instances of encryption, but the fact remains that there is very little separation between good and bad behaviors when considered in isolation. Patterns of behavior are more promising, and a data scientist could design the experiments necessary to determine the discrimination power of patterns of different lengths or types and to develop a feature set that is robust and practical, and reduces error.
The data scientist could also run experiments to determine where to set the threshold when scoring good vs. bad behaviors. It is important to remember, however, that in cybersecurity, not all errors are created equal. The difference in the consequence of different error types can be significant. False negatives or missing a bad behavior can lead to significant business consequences such as data loss, system damage, or denial of service.
There is real dollar value in avoiding this type of error. False positives, on the other hand, lead to alert fatigue, and possibly to a delay in response. While these are annoying outcomes that should be avoided, they rarely make headlines. Understanding the enterprise’s sensitivity to various types of error is key to determining thresholds and other parameters. A data scientist can incorporate this sensitivity into the threshold-setting process (https://thehackernews.com/2022/08/the-truth-about-false-positives-in-security.html).
In addition, cybersecurity analytic solutions often leave operators confounded because they do not make the confidence level of the machine decisions apparent to the user. Users tend to trust applications with which they have become familiar, and to take the results of these applications at face value. Because of the overlapping distributions and the difficulty of placing decision thresholds, this trust is often unwarranted. Machines will boldly categorize data that just barely passes thresholds with data that pegs the scale. This leaves no opportunity for nuanced responses or for automated workflows that queue up follow-on testing.
The data scientist can develop methods to expose the confidence level to human or machine decision-makers or scoring methods that incorporate confidence into the score. This, in turn, enables smarter workflows that speed up the time to decision.
Finally, it is difficult to introduce context into many threat-based cyber analytics, but context should be a critical factor in any cyber response decision. Without it, the enterprise may overreact to a bad behavior that is of little consequence or ignore a bad behavior that is ranked as a low risk for systems in general but poses a high risk for the particular business of the enterprise.
Here again, data science input at design time can make it possible to develop feature sets that are context-dependent or algorithms or workflows that are conditioned on context.
Having seen several ways that the data scientist can improve cyber analytic technology by bringing good statistical practice to bear, it’s time to look at how they can improve the notion of risk embodied in this analytic technology.
The cybersecurity marketplace is replete with threat-based and vulnerability detection technologies. There are even technologies that provide “risk scores” based on the detection of vulnerabilities. But risk and threat or vulnerability are not the same, and enterprises need to be concerned with risks, not threats or vulnerability.
Cyber risk is the product of four factors: threat, vulnerability, likelihood of exploitation, and impact. Unfortunately, many enterprises have overinvested in underperforming cybersecurity technology because they have concentrated on addressing only the first two of these factors in isolation. A new threat emerges, a new solution is added to the security architecture. Vulnerabilities are found, new technologies are purchased to address them.
Yet a system may be architected in a way that neutralizes the new threat (you have zero trust access control, which limits an intruder’s ability to execute). Existing cyber controls may already close the vulnerability (your email service may have built-in phishing detection). The attack may be a type that is not likely to affect your enterprise (a close-access threat, which is typically used in a targeted way against high-value targets). The impact on your system may be small (you have solid backup technology, so ransomware won’t trouble you).
To develop risk-based defense or response strategies, each of these factors has to be decomposed into its contributing subfactors; the interaction of those subfactors must be modeled; and then the interaction of the factors must be modeled, ideally in a formula that produces a score that can trigger human- or machine-driven action.
To address this complexity and develop this formula, the data scientist must collaborate with the system architect and the security engineer. It is not enough to simply take a binary view: threat present or not, vulnerability present or not. Rather, data scientists must build more-complex threat models that take account for a multitude of factors, such as cost or difficulty of attack, whether a code vulnerability is executed under typical inputs or rarely reached, likelihood of being attack at random vs. targeted for attack, value of system or data, effectiveness of mitigating controls, and many more elements.
The risk modeling problem becomes even more complex when considering that these factors are interdependent in some cases. It is also difficult to learn the risk model using AI, since attacks, although well-promulgated, are in fact quite rare as a percentage of computations executed by a system. Further, it is not clear how large a data window must be before an attack or which observations and features are relevant.
Developing an adequate training set would be a daunting problem. Nonetheless, a realistic risk model would change the game for cybersecurity decision-making, and new data-scientific methods to build such a model are much needed.
Adequately modeling adversarial behavior remains a problem. Cyber attacks are not random processes, but rather intentional activities. Unfortunately, many cyber analytic approaches are built on the assumption that cyber attacks can be treated as random processes and leave out any understanding of the adversary as a factor in analysis. This assumption is not disastrous, and untargeted annoyance attacks are close enough to random for current analytics to be somewhat successful. However, more-complex targeted attacks are far from random, and ignoring adversarial behavior when considering such attacks creates a distorted view of the threat to the typical user.
Many cyber solutions are over-engineered to address threats that are troubling in principle but simply make no sense from the point of view of adversary tradecraft.
There is much discussion of adversarial modeling in cryptography, which can shed some light on the problem in cybersecurity in general. For example, Do, Martini, and Choo (2018) discuss several such models in terms of the adversary’s assumptions/situation, goals, and capabilities. Under this construct, it is clear that the adversary is not acting randomly, nor playing a game that can be conveniently modeled with game theory. Rather, they are trying to accomplish something—to achieve a goal. This can help refine the understanding of risk.
Advanced, persistent threats are not going to attack Grandma, nor are they likely to attack Joe’s Garage. There is often lots of fanfare about the latest zero-day close-access attack and its potential to do damage, but most of us will be just fine. Understanding risk can help us understand whether we should worry, but for those who should worry, critical infrastructure providers, holders of valuable data and so on, understanding the adversary’s assumptions, goals, and capabilities can help with crafting a more realistic and effective response to the threat. The data scientist can investigate methods to incorporate a rich model of adversary behavior into systems as they are being developed.
As shown, there are several ways that current practices in cyber analytics suffer from the lack of a nuanced understanding of data and data modeling. This lack of strong cyber data science can help explain the growing frustration with large enterprise investments in cybersecurity technology that often underperforms. The extent to which these technologies lack scientific grounding in their use of statistics, use impoverished risk models, or fail to consider adversarial behavior, is the extent to which they miss the mark in grounding cyber decisions. There is much to be gained in moving the practice of cybersecurity from a data-driven to a data-science-driven domain.
Further Reading
Do, Martini, and Choo. 2018. The Role of the Adversary Model in Applied Security Research.
About the Author
Pat Muoio is an expert in matters of cybersecurity and computing, vetting the technical viability of emerging technologies. She had a 30-year career in the intelligence community in a variety of technical and leadership positions, retiring as chief of NSA’s Trusted System Group, a job that involved strategic research planning and the management of dollar and personnel investments. She currently is a general partner in Sinewave Ventures. Muoio has a BA from Fordham University and a PhD from Yale, both in philosophy.








