
Keep a Human in the Machine and Other Lessons Learned from Deploying and Maintaining Colandr

A Brief Introduction to Evidence Synthesis
The exponential growth of scientific output—by some measures, expected to double in less than a decade—means that researchers, practitioners, and decision-makers must dig through a near-overwhelming amount of information to find relevant evidence to inform data-driven decisions. Systematic evidence synthesis approaches are credible methods for finding, assessing, and synthesizing reliable evidence insights from this ever-growing volume of information.
These approaches include various methods, from in-depth systematic reviews and broad systematic maps to rapid reviews. They are valuable because they aim to use transparent and reproducible methods to assess the evidence base comprehensively, providing a template for updating synthesis projects to serve as dynamic, living evidence resources.
While systematic evidence syntheses have tremendous potential to facilitate evidence-informed decision-making, conducting these methods typically requires manually searching and screening through thousands, if not tens of thousands, of potentially relevant documents. An assessment, conducted by the Colandr team, of searching efficiency in syntheses published in the environmental sector found that just 2% of documents end up being included as relevant. This labor-intensive process is not only time- and resource-intensive, but can also be prone to error because it is driven by human decisions.
As the global body of research continues to grow exponentially, so does the need for faster, more-efficient ways of finding relevant literature (e.g., semi-automation) instead of the common brute force methods. Technical advances in human-assisted machine learning and data visualization have the potential to substantially reduce the human effort needed to separate the proverbial evidentiary “wheat” from the “chaff.” In response, a proliferation of different tools has developed for harnessing the power of machine learning, text mining, and natural language processing for optimizing the process of evidence synthesis.
From 2015–2017, DataKind, a global nonprofit that uses data science, machine learning, and artificial intelligence in the service of humanity, partnered with the Science for Nature and People Partnership (SNAPP) Evidence-Based Conservation Group and Conservation International to tackle this problem, which is shared among many sectors.
The problem: how to digest the amount of evidence available to inform decision-making in a way that would still allow for timely decisions. So grew Colandr: an answer to the question of “How can we apply machine learning and natural language processing algorithms to make this process of synthesis faster, more efficient, and more affordable?”
The experience of launching and maintaining Colandr has moved from defining the key functionalities to collaborating on architecture to stewarding a global user experience. This article details the learnings of the Colandr team along the process and contains recommendations and a call to action for future contributors.
Defining Key Functionalities for Colandr
When Colandr launched in 2015, there were few collaborative evidence-synthesis tools, fewer still with built-in machine learning, and none (that the team was aware of) that contained both features and were also free. To respond to these gaps involved producing a tool designed as a free and collaborative alternative to evidence synthesis practices using non-specific tools (e.g., Google Sheets) or fee-requiring specific tools (e.g., EPPI-Reviewer).
To be successful, Colandr had to improve on current pain points with evidence synthesis and be free, open-source, and publicly accessible. It also had to be dependable, with limited downtime, so the general public could use it to inform evidence uptake.
Fundamentally, Colandr had to follow the defined process and criteria of a systematic review. In addition to that functionality, the tool itself had to perform four primary functions with consistency and accuracy to meet the minimum threshold for success.
First, the tool had to de-duplicate records successfully. A systematic review requires users to pull information from several databases, with records often extracted from multiple sources; de-duplication efforts ensure that the results are not skewed.
Second, the process had to incorporate a relevance ranking to speed up the citation review process.
Third, Colandr had to allow for automated data extraction—e.g., surfacing critical pieces of evidence from papers—to make it easier for humans to review relevant information efficiently.
Fourth, the tool had to be able to complete document classification as defined by the user.
Figure 1 details the final review framework.
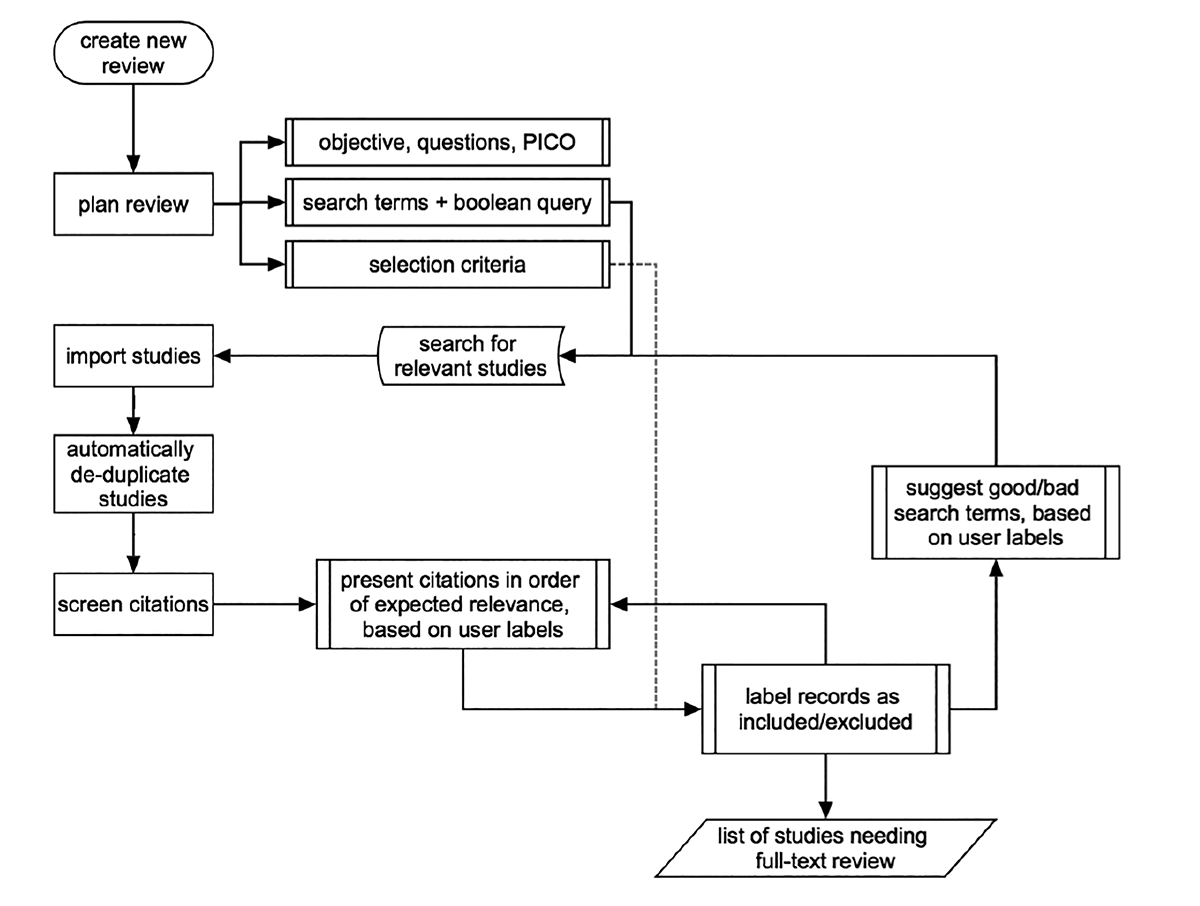
Figure 1. Framework for Colandr’s evidence-synthesis process.
Designing the Technical Framework for Colandr
While machine learning approaches in 2015 had already been successful in automatically sorting and extracting data in specific fields (such as health), researchers described similar methods as “challenging” for the conservation sector due to semantic complexity and non-standard terminology. However, as the project began, several researchers demonstrated academic success in using machine learning for ecological topic modeling and distinguishing between homonyms in conservation. Encouraged by this scholarly work, the Colandr team wanted to incorporate the power of machine learning alongside human-centered design to create an innovative new solution.
Ultimately, Colandr required a graphical user interface and an algorithmic backend to support the core functionality. This backend architecture is needed to provide processes for data acquisition, supervised learning, and natural language processing techniques to acquire, then classify and extract information from research publications.
The team of pro bono technologists and data scientists from DataKind and researchers from SNAPP developed two free and open-access web-based processes for computer-assisted paper review and evidence management (System 1 and System 2, detailed in this article). The client-side Colandr application is a web application written with modern HTML5/CSS and Java-Script (specifically, ECMAScript 2015). The application is served with ExpressJS and Nunjucks templates and makes server-side REST calls to the two Python APIs (System 1 and 2) to retrieve and update data.
System 1: Full-Text Screening
System 1 in Colandr is designed to speed up the first review step in evidence synthesis: systematic map or review to include or exclude materials in the review. It is a decision made based on title, author, keywords, and abstract (commonly referred to as “citations” when creating systematic maps and reviews). Each new review conducted in Colandr starts from a blank slate, and the user (referred to as a “reviewer”) must input their own corpus of citations and generate their own labeled data.
System 1 takes user-defined search terms and computes the amount of overlap between those terms and the preliminary review information for a human to review and decide to include or exclude the citation. As humans make these decisions, System 1 takes in those newly labeled data. After enough data have been labeled, System 1 switches from assessing relevance based on these similarity computations to using a more-complex classification approach using distributional word vectors (word2vec).
Word2vec, first published in 2013 by a team at Google, is a family of algorithms (models) for natural language processing. These models represent each word as a vector and compute the relative distance between words in a corpus to describe the “semantic similarity” of words or phrases. The word2vec models and outputs can be used for text classification and the ultimate categorization of new text data.
However, to maintain transparency in the process, Colandr does not automatically include or exclude citations, but requires users to make that decision. Trialing System 1 with an existing systematic map data set (created through manual review by SNAPP team members), the Colandr team found a significant improvement in material selection efficiency. Manually, reviewers had to read nearly 1,500 citations to identify 100 for inclusion (a rate of approximately 7%). Using Colandr, reviewers screened 250 citations to find 100 (with the model re-ranking relevant citations every 10) for an inclusion rate of 40%.
Thus, as the volume of training data grows, the confidence of model predictions of relevance improves correspondingly, dramatically decreasing the amount of citations that a reviewer has to sift through for relevant ones. This relevance ranking can also be toggled on and off—a user does not have to engage with the ranking system to use Colandr to conduct a review.
System 2: Evidence Extraction
Extracting evidence (commonly called “metadata” by reviewers) from included studies typically requires reviewers to read entire articles and manually code desired features (bibliographic information, geographic area, conservation type, etc.). System 2 was designed to make this frictionless by providing processes for semi-automatic metadata classification.
System 2 does this by extracting sentences from articles it identifies as relevant to the desired evidence tags. For location features, Colandr relies on a “Named Entity Recognition” technique to find mentioned locations in the document and suggest these as labels. For other metadata, Colandr relies on global vectors for word representation (GLoVE) and logistic regression to train a model of ranker-tags.
GLoVE, which began as a Stanford University project, has been deployed within Colandr to identify relevant metadata evidence based both on the text classification and the location of the evidence within an article. The GLoVE model process can be trained to predict the likely relevance of individual sentences to desired evidence labels and present those options to the user to inform manual classification.
With this mechanism, Colandr uses training data generated through the review (relying on a minimum of 35 logged decisions) to provide provenance for predicted labels, allowing it to function over a broader range of data sets incorporating varying levels of linguistic complexity and feature representation. Colandr shows the sentences that it believes best support the evaluation of metadata to the user, who can then use that information to pick the correct labels.
System 2 intentionally over-predicts so the system can focus on recall, while human annotators can focus on precision. While System 2 does not necessarily improve the rapidity of data extraction, it can improve accuracy by catching missing or mislabeled features.
Lessons Learned from Creating Colandr
As the team built Colandr, it became clear that true automation was not possible because of semantic variability. In the early design, the team faced significant challenges in the amount of data and imbalanced labels for desired metadata. These imbalances led to poor model performance in the initial technical approach and are the primary reason why Colandr does not label research papers automatically.
However, true automation was not always the best solution. This was evident through discussion with teams working in conceptual spaces where concepts and typologies are debated or evolving. It was particularly salient for actors working on multi-disciplinary questions. Within the testing and development community, retaining a degree of user oversight actually improved trust in Colandr and potentially widened its user base. In effect, “keeping a human in the machine” ended up being a desired, and ultimately core, feature of Colandr.
Collaborating on Colandr as a Stewarded Public Resource
At the time Colandr was launched, there was a need to fill a void in research infrastructure. Existing systematic reviewer tools had excellent graphic user interfaces, but still required a human to do all the work (and some were pricey). While the original request was for a tool for conservation and environmental sciences, the Colandr team ended up building a tool that is useful across disciplines.
This project set an example, and de-risked the space for others looking to build and deploy their tools to assist in systematic evidence syntheses and information review efforts. Colandr became a viable, useful, community-stewarded research tool that has been cited in at least 30 publications and had more than 1,000 users across the globe as of summer 2021.
Users hail from research institutions, nonprofit organizations, private companies, government agencies, and information support services. They are conducting more than 700 active reviews spanning a wide range of topics: public health and medicine, education, environmental science and agriculture, international development, social science, and conservation as a representative list.
The team also struggled over the past half-decade because Colandr launched as a commercially competitive tool, but without a commercial budget for maintenance or ongoing development. The American Museum of Natural History has helped mitigate many of these risks by stepping in as a technical and financial steward and to ensure that Colandr continues to function, but support primarily rests on a volunteer team. In practice, this means that Colandr relies on volunteers to maintain the server, troubleshoot with users, and actively engage in server restarts, and on a volunteer developer community to keep pace with software improvements.
Colandr is built on open source tools that are constantly evolving, and its creators also must be able to keep up with the pace of developments so it continues to function in the manner intended. Colandr also has known limitations based on the volunteer community’s interest and skills. For example, Colandr will be an English-language-only tool for the foreseeable future.
However, that community of practice has been critical for crowd-sourcing development ideas and opportunities for evaluation.
Colandr was intended as a first demonstration of success in the sector, and a framework that others could extend. By providing an open source tool and building a community of practice, it has been able to grow in functionality through the contribution of complementary user-generated tools and guides. For example, two additional tools have been built and have platforms in the community: visualizing results and downloading bespoke data sets (Colandr companion) and guides for file retrieval and conversion.
These tools add efficiency to the process of creating a systematic map or review. As the fields of open research infrastructure and digital public goods continue to evolve, there will be increasing relevance and opportunity for Colandr and similar tools.
Recommendations and a Path Forward
In developing Colandr as a first mover, the creators intended to facilitate a conversation about machine learning benefits and risks, and automated evidence detection in evidence synthesis projects. While not exhaustive, the experience of developing and testing Colandr, and stewarding a collaborative research community, has provided novel insight into mainstreaming machine learning in evidence-based practices. These recommendations can encourage increased engagement with the development and use of open research tools.
1. Follow open source development best practices. As a minimum standard, all underlying algorithms should be made open source to facilitate future efforts to build and improve current tools. Future development efforts should follow standards similar to the Digital Public Goods Standard, a set of specifications and guidelines operationalized by the Digital Public Goods Alliance to reduce fragmentation in the digital space in support of the United Nations 2020 Roadmap for Digital Cooperation.
2. Evaluate performance. How well a tool performs can only be known if users are willing to test it systematically. In the absence of established organizations to lead validation efforts, users are encouraged to help advance the field by posting feedback and evaluation through the Colandr Community and other open resources such as the SR Toolbox.
3. Share data sets. Individuals conducting evidence synthesis with tools that integrate machine learning can transparently report inclusion/exclusion criteria and screening decisions to ensure reproducibility and external validity of methods. Conservation, as a multidisciplinary field, so far does not have consistent term ontologies. With considerable variation in synonymous terms, having detailed and rich data sets for training is critical for improving accurate predictions of relevance. Review teams can improve the training of machine learning algorithms by sharing their screening decisions.
4. Form collaborations. Scientists can form partnerships with developers and computer scientists actively engaged in machine learning, web platform development, or open source maintenance rather than attempt to “hack” their solutions to ensure long-term tool sustainability.
Further Reading
Cheng, S.H., Augustin, C., Bethel, A., Gill, D., Anzaroot, S., Brun, J., DeWilde, B., Minnich, R., Garside, R., Masuda, Y., Miller, D.C., Wilkie, D., Wongbusarakum, S., and McKinnon, M.C. 2018. Using machine learning to advance synthesis and use of conservation and environmental evidence. Conservation Biology 32: 762–764.
Kohl, C., McIntosh, E.J., Unger, S., et al. 2018. Correction to: Online tools supporting the conduct and reporting of systematic reviews and systematic maps: a case study on CADIMA and review of existing tools. Environmental Evidence 7, 12.
Mikolov, Tomas, et al. 2013. Distributed representations of words and phrases and their compositionality. arXiv preprint.
O’Mara-Eves, Alison, et al. 2015. Using text mining for study identification in systematic reviews: a systematic review of current approaches. Systematic Reviews 4.1: 1–22.
Pennington, Jeffrey, Socher, Richard, and Manning, Christopher D. 2014. Glove: Global vectors for word representation. Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP).
van de Schoot, R., de Bruin, J., Schram, R., et al. 2021. An open source machine learning framework for efficient and transparent systematic reviews. Nature Machine Intelligence 3: 125–133.
About the Authors
Caitlin Augustin is responsible for delivering DataKind’s core offerings, ensuring that high-quality, usable data science interventions are created in partnership with social sector leaders. Before joining DataKind, she was a research scientist at a digital education company and an engineering professor at New York University. She is engaged with Central Florida’s nonprofit community and the organizer of the Orlando Lady Developers Meetup. Augustin holds a BSIE and PhD from the University of Miami.
Samantha H. Cheng is a biodiversity scientist at the Center for Biodiversity and Conservation (CBC) at the American Museum of Natural History whose research draws from the biological, social, and computer sciences to understand connections between nature and human well-being in global communities and drivers of marine biodiversity. She runs two online open access tools to facilitate assessing and accessing evidence—and coordinates the U.S.-based center with the Collaboration for Environmental Evidence at the CBC. Cheng has a PhD from the University of California, Los Angeles.








