
Data of the Defense and the Defense of Data

Suppose that Bob’s internet connection is running unbearably slowly and he would like a technician to drop by his home to understand and solve the problem so he can get back to streaming “Homeland.” However, after having seen a couple of seasons of this TV series, Bob has become quite concerned with possible security and privacy issues when he invites people into his home. As a consequence, when Alice (the technician) shows up at his front door to help solve his problem, Bob starts asking for a long list of certifications and background checks before he will let her in. Although Alice would like to help Bob, she does not feel she can spend the time, effort, and costs required to fulfill Bob’s conditions for being helped.
In this scenario, Bob represents any agency working with or in the United States Department of Defense (DoD). Just as Bob wants to improve and optimize the quality and speed of his internet connection, the DoD has shown great interest in and made funding available over the past years to external data analysts to extract the most-useful information possible from its data and optimize its administrative, operational, and strategic decision-making procedures. However, even more than Bob, the DoD has put extremely strict and rigid protocols and procedures in place to grant access to such data, severely limiting the number, nature, and diversity of service providers in this domain.
While some of the data sets held by the DoD are considered classified and require clearances to gain access to them, many more data sources are unclassified—yet still considered sensitive. Such data sets are referred to as Controlled Unclassified Information (CUI), and, in true government fashion, significant red tape still restricts access to them. These restrictions cause bottlenecks even as agencies push to share data.
While the concept of sharing data sounds good in practice, data custodians are timid about releasing data they are responsible for, in part because of fear of what their enemies might be able to learn from the data. No one wants to be responsible for a data release that could harm Americans or become an accessory to espionage, right? The de facto answer to this question has been to err on the side of caution: restrict, restrict, restrict.
For example, the U.S. Army funded the creation of a competitive environment for potential vendors in 2018 to showcase their ability to develop algorithms to automatically identify mechanical failures in wheeled vehicle data (Applied Research Laboratory competition, Penn State University. 2017–2018). All data were considered CUI, so the Army developed appropriate certification processes and restrictions for all competition participants.
There was significant initial interest from the private sector, since many groups were (and still are) marketing advanced condition-based maintenance capabilities to the Army.
As the project progressed, though, very few contenders were able to navigate the challenges associated with accessing and analyzing CUI data. Initially, 21 organizations showed interest in participating, yet only 11 followed through with the access procedures to be granted access to the data. Of those 11, only two completed data analysis and provided reports about their results.
Examples like this show just how burdensome access restriction can be, leading to the question of whether there is any way that these protocols and procedures can be loosened to favor sharing useful data.
Defending the Data of Defense
There are three general responses to that question: a) Continue with the current protocols and hope that a competent, strong-willed vendor/contractor will battle through all the (expensive) red-tape hurdles; b) release the data directly and risk sharing sensitive information with attackers; or c) modify the data to have a lower risk of releasing sensitive information when sharing it, but at the potential expense of less-useful data.
The first option is the current status quo and the second is clearly off the table; the third option might not be viable for classified information, but deserves exploration for unclassified data, including CUI.
In many cases, DoD data will be treated as CUI due to only a handful of sensitive variables in the entire data set. In addition, these sensitive variables may not be that interesting to DoD sponsors or researchers. Can these variables simply be removed or renamed, and the data resulting from these operations shared? To answer this question, let’s play the role of a privacy expert.
Here are some data release scenarios. For each example, think about what potential problems might arise. Their weaknesses may surprise you.
Example 1. Charles is part of the agency responsible for keeping America’s troops in all service branches, all over the world, stocked with necessary parts and supplies. To optimize how many nuts, bolts, and O-rings the government purchases and where they are all stored, Charles wants an outside contractor to analyze the supply of and demand for various parts. However, he isn’t able to release details about which locations order certain components, since that could reveal where various weapons platforms are staged.
Charles downloads a sample of the data, and then transforms the “receiving location” variable to be a meaningless categorical variable; rather than releasing the actual name of a specific air base, fort, or port, the data set is released with locations only identified as “A,” “B,” or “C” (and so on). He then shares this “privatized” data set.
Example 2. Alice, a data administrator at a naval hospital (and internet technician in her spare time), is charged with preparing a data release of sailors’ health records to improve patient care. Her boss wants her to release information about all admissions over a certain time frame so outside users can determine whether the hospital is using its resources efficiently.
Worried about privacy, Alice removes all names from the data set and replaces birth date with patient’s age range. She approves these data for release.
How do you grade Charles’s and Alice’s privacy schemes? While they get bonus points for even thinking about privacy, there are some potential issues.
In Charles’s case, the obfuscation of the location identifiers should intuitively do the job. In the same way, removing names and placing ages into larger brackets (with other patients) should allow Alice to release the modified data without fear of patient identification. However, there are at least two big areas for concern: other outside information that might relate to the data release and indirect identification through information leakage.
When deciding whether to release information, the data curator should not only consider the information they release to the public but also take into account the information that is already in the hands of the public (more specifically, in those of malicious attackers). The information coming from certain other variables or the connection that these variables have with outside data sources can severely compromise the privacy of the sensitive variables (identifiers).
In Charles’s case, reading a few Wikipedia pages could help an attacker pinpoint a specific location. In Alice’s case, other personnel files could be linked to the health records and potentially boost the amount of information an attacker could gain.
Another important point to stress is that observations can be more unique than they appear at first glance. William Weld, the former governor of Massachusetts, found this out the hard way. In 1997, he decided to release data about the health records of state employees in the name of transparency. Since the taxpayers were footing the bill, shouldn’t they know where their money is going? For the sake of privacy, he had the data of names and Social Security Numbers scrubbed. What could go wrong? Hint: a lot.
Weld failed to realize how much other information in the data could uniquely identify an individual. Think, for a second, how many other people who live in your ZIP code share your exact date of birth and gender. For most people, the answer is not a lot. The health records that Weld released contained this level of detail, which was not a problem on its own. However, this same information can commonly be found in other publicly available data sources. In the case of the governor, a smart researcher named Latanya Sweeney linked the health records with publicly available voting rolls, easily identified the governor using his birthday and city of residence, and sent his health records off to his office.
Even scarier? This type of scenario isn’t unique, and examples like this are a dime a dozen. Another example is when Netflix decided to release their movie ratings database in a competition: Some researchers showed that combining the Netflix data with iMDB movie reviews resulted in some reviewers being uniquely identified.
The list goes on.
How might this affect Alice and Charles?
For Alice, it could be that knowing that someone has a relatively rare condition or a combination of several common conditions could allow someone else to pinpoint them exactly and infer the rest of their medical records.
For Charles, the risk follows the same spirit: If a benign-sounding, yet oddly specific, part (like a specific O-ring for cold temperatures) is only delivered to forts A and N, then an attacker who has prior knowledge of (i) which vehicles use this specific part and (ii) the only two locations that house these specific vehicle variants can identify those locations by name.
So far, the malicious actor hasn’t learned anything new. However, this individual can work backward: This information can be used to identify the posting location (by name) of any other weapon platform that uses parts that are shipped uniquely to Forts A and N.
Can Privacy Save the Day?
The management and treatment of sensitive information has been a topic of public debate and research dating back to the mid-1900s, but has grown exponentially over the past decade due to the enormous amount of data collected by corporations and governmental agencies. Thanks in part to federal law, some of the biggest proponents of data privacy have been other U.S. government organizations.
For example, if you navigated to the U.S. Census Bureau’s website and accessed data releases for some of their main products, you might reasonably expect that you have access to the true, unchanged data collected by the Census. However, chances are high that you would be mistaken.
While some information must be true to what they collect (they aren’t fudging the population of Pennsylvania), other information undergoes a disclosure avoidance review and probably has had some privacy methods applied. In the case of the Census, these privacy methods are only going to get more stringent because the Bureau has pledged to adopt formal privacy methods for some major releases in the future.
Even though DoD data may present different problems that cannot be tackled by current approaches, many privacy methods might hint at some potential solutions, including the general setting. Data privacy methods balance the quality of data released with the risk of disclosing sensitive information. This balance is often referred to as the risk-utility trade-off. Many privacy methods have been introduced to achieve this balance, but they are not created equally.
Depending on the nature of the data, some methods might not provide enough distortion to protect sensitive values sufficiently. Others may alter the data too much, releasing “privatized” versions that are so different from the original data that analyses done on the private data cannot faithfully answer questions about the original data. However, most methods have one thing in common: Variance and bias are carefully injected into the data to “protect” the observations.
In fact, we have all seen data privacy methods at work without even realizing it. For example, consider a survey that collects income data for a certain group of people. These results could be reported in several ways.
- Incomes could be released directly as is (a high-utility/high-risk situation).
- Top-coding would leave all data alone except high incomes (say, above $500,000), which would be reported as “$500,000 or above.”
- Coarsening would report incomes in ranges of dollars instead of exact dollar amounts.
- Yet another option would be to add random noise to each value directly.
The list of potential solutions goes on and on.
These privacy methods are just the beginning. More-rigorous methods have been developed, including synthetic data: Instead of releasing the data directly, synthetic methods attempt to model the underlying data distribution and release samples from that model instead.
At first glance, this seems like a perfect privacy method; since no true data are released, risks of disclosure should be very small. Theoretically, yes. Practically, no. In short, no true data are released, but remnants of the original data can still leak through. This leakage can result in synthetic observations that are uncomfortably similar to the real ones.
Can this information leakage be controlled? Not quite exactly and, at least, not for free. We can, however, create our own definition of risk and try to construct privacy measures that meet these definitions. Methods known as formal privacy do just that by creating mechanisms that meet certain mathematical definitions of disclosure risk. The most commonly known and used method is differential privacy, which bounds the maximum change in an output (think of the sample average), regardless of whether a certain observation is used in calculating that output.
This framework (as well as other privacy approaches) aims mainly at protecting the rows of the data (e.g., the individuals whose data are collected) and consequently does not necessarily protect the “nature” of the data (e.g., whether the data in a certain column reveal sensitive details about the limits or capabilities of a given machine).
While formal methods are relatively new, there is an increasing amount of interest in adopting differential privacy in data releases. The U.S. Census Bureau plans to use differential privacy for the 2020 Census and 2025 American Community Survey (ACS).
Once there is a privatized data set, the next step is to get it to users. There are plenty of ways to do this, and again, other government organizations can offer some potential solutions for the DoD. Obviously, the data could be released directly, such as by posting on a website, which is how the Census Bureau releases its Census and ACS products.
Alternatively, if even the private data need a bit more security, they could be released on a restricted access server. This is a good approach—as long as access to this server is less-restrictive than access to the original data. Otherwise, it defeats the purpose of private data. Data could be released directly with no warranty, or could be used as a tool to develop code and models before access to the original data is granted or results are verified by the data curator.
A simulated data set of a 3-D surface can illustrate how some privacy methods behave. You might see an airplane nose or a submarine hull. Two types of privacy methods can be applied to the simulated data. The first method features private data using synthetic data routines based on Classification and Regression Trees (CART). CART is a machine learning technique that, generally speaking, aims to find the best splits in the data so certain values of a variable predict a certain outcome more than others.
The second method uses a differentially private method based on adding noise to the histograms of the data (which consequently modifies the number of observations in each range of values) appropriately. Figure 1 shows plots of each approach for a data set with n = 5,000< observations.
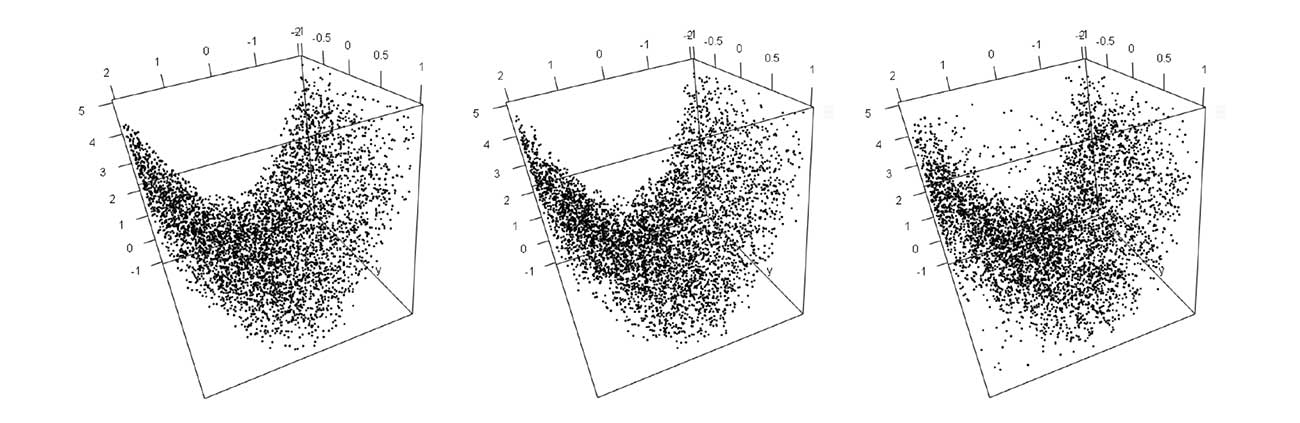
Figure 1. Original simulated data (left) compared to two private data sets: CART synthetic data (middle) and differentially private histogram approach (right) (n = 5,000). Both privacy methods introduce distortions when compared to original data.
Looking at the figures, what do both privacy methods have in common? They both distort the data, although to different levels. Who’s the “winner”? That depends. How risky are the original data? Who is going to have access? Are their any specific analyses of interest?
For example, the privacy methods appear to preserve the “hull” structure and, consequently, will not be useful if this is a feature that the DoD wants to protect. On the other hand, modifying the data to the point where the structure is completely changed defeats the purpose, since extracting meaningful information from the data is no longer possible. Hence, the selection and implementation of privacy methods will depend on the ultimate goal. If the goal is to obtain reliable analyses, while making the user uncertain about whether the data comes from the hull of an airplane or a submarine, then the privacy method in use can definitely play a role.
Saving Private…Data
How can a practical application of privacy methods blur the picture when analyzing data of relevance for the DoD?
In this case, you’re the contractor to whom the DoD has assigned the analysis of their data to provide meaningful insight and possible tools to analyze this kind of data in the future. The quality of your analysis will, obviously, depend on the data made available: If you receive the original data, then your analysis will be reliable (if you’re a reliable analyst), but if you receive a privatized version of the data, your analysis could actually deliver tools and conclusions that differ from those that would have been obtained on the original data.
A real data set, publicly available on NASA’s prognostics data repository and non-sensitive since it is simulated, can help highlight these issues. These data report different sensor measurements regarding the functioning of a generic, unidentified model of a jet engine. It is similar to many real DoD data sets that are being used to research how machine learning can pinpoint the degradation of components in a given machine (like a turbofan engine) to make maintainers more effective.
However, despite removing/modifying direct identifiers, these data often contain information that can allow attackers to understand the type and strategic location of vehicles. Consider the following.
Example 3. Bob is an engineer who is part of the management group for maintaining all instances of one specific tank model in the Army. The tanks his group maintains automatically collect and store temperature, pressure, speed, and other sensor data from the tanks’ engines, while a separate system digitizes and creates databases of all the maintenance records that soldiers painstakingly record by hand.
Bob wants to study whether a machine learning algorithm exists that can use the sensor data to predict engine failures in the tanks. While Bob realizes he needs to share both data sets, he also knows that the unit operating each tank and the maintenance depot (location) a tank is sent to for certain maintenance activities (both included in these data sets) cannot be released to the public: Doing so would reveal detailed information about which tank-operating units are posted where around the world.
Bob (who, in the meantime, is still trying to solve his internet connection problem) knows that, in a similar data set, researchers at Penn State’s ARL were able to reconstruct the exact routes that certain trucks drove. They did so by using auxiliary information, even though the “protected” data had removed exact locations. Knowing that removing information is not enough, Bob intends to release a private version of the data and has options available for this purpose (as seen earlier). His goal is to release these data in a way to control the risk that certain sensitive information is leaked while allowing you (the contractor) to do your job as best as possible.
In many cases, the choice of which privatization technique to use depends on the type of analyses that you expect to be applied to the data. However, Bob (and the DoD in general) does not necessarily know what kind of analysis can be done to reveal helpful information, and therefore wants to release data that should be useful regardless of the type of analysis run on the information. The privatization, therefore, must be done independently from the possible analyses made.
Generally speaking, the goal of the DoD when releasing the data is to understand what kind of analyses can be performed to help their case. For the purpose of illustration, assume that you receive the data from Bob and your job is to provide a method that predicts the remaining lifetime before engine failure as best as possible. If this remaining lifetime is denoted as a possible method is Linear Regression (LR), where y is explained through this equation:
y = α + 𝓍1β1 + 𝓍2β2 + · · · + 𝓍pβp
where each 𝓍 is a measurement (variable) from a specific sensor and each β (that we want to estimate from the data) measures how the remaining lifetime y changes when these variables change (α is not considered for the purposes of this illustration).
The variables that make up these x values are different physical sensor measurements from around the engine: temperatures, pressures, fluid flow rates, and speeds.
All of these sensors tell a little part of the story of how the engine is being used at any given moment.
Given this, the goal is to understand whether they can also tell the story of how much longer the engine can be safely used. It is a reasonable guess that some combination of these physical parameters will give information about how healthy the engine is, but, without being an expert in the complex fluid dynamics at work inside the engine, it is hard to pinpoint exactly which ones will do best. Maybe the temperature and pressure at the exit of the engine, when compared to the simultaneous temperature and pressure at the inlet of the engine, can say something about how smoothly air flows through the engine. Pressure, temperature, and volume of a fluid are all related directly by the universal gas law, right?
These are the kinds of underlying physical principles Bob is counting on to connect all of these sensor readings together to paint a single, cohesive picture of the engine’s health.
Considering the complexity of how all these physical phenomena (measured by the sensors) can interact to predict remaining lifetime, other approaches can be considered aside from the LR method, such as those based on Generalized Linear Models (GLM), Random Forests (RF), or Multivariate Adaptive Regression Splines (MARS), to mention just a few. If you had access to the original data, then you would be able to provide Bob with the best method based on your statistical knowledge. But would you suggest the same method if you were given private versions of the data? As shown earlier, privacy methods blur the data and could, therefore, lead to a different choice.
Could some privacy approaches change the choice with respect to the preferred method among LR, GLM, RF, and MARS? To measure how good a method is, chose various metrics such as the typical ones used for diagnostics and prognostics for the DoD. The “utility” of a method will depend on the goal for extracting results from the data. This example simply uses the (in-sample) Mean Squared Prediction Error (MSPE).
Regarding the chosen privacy methods, the range of a given sensor’s measurements may give away physical characteristics that are specific and sensitive to certain engines, no matter how much noise is added for privacy. For example, too much noise would be needed for temperatures and pressures for a plane or submarine engine to appear similar in the data. We therefore chose to scale the measurements for them to all be within similar ranges before applying privacy methods.
Considering CART and differentially private approaches to generate data, the final goal of these mechanisms is to ensure that it is extremely difficult for an attacker to distinguish the engines from each other and make it hard for them to extract precise information about the types of engines and the locations where they are being used.
Table 1 collects the MSPE for the four considered prediction methods (LR, GLM, RF, and MARS) as applied to the original data and the two privacy mechanisms considered for this example. The first column represents the results if applying these prediction methods to the original data (as a reference, or gold standard).
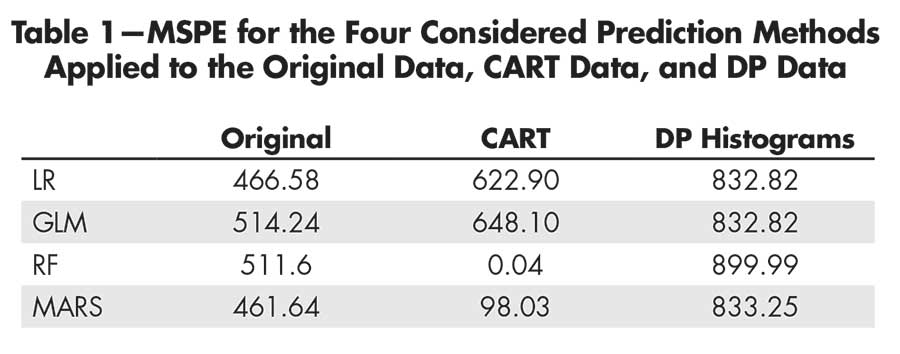
Table 1—MSPE for the Four Considered Prediction Methods
Applied to the Original Data, CART Data, and DP Data
Given that the best method appears to be the MARS, ideally this would be the chosen method when using the private versions (which are what you would be working on).
The second column represents the MSPE when applying the methods to a CART synthetic version of the scaled data. In this case, the RF is by far the best approach; CART synthetic data are based on the same method that the RF uses and this approach would possibly perform better. Would this mean that we would tell Bob to use the RF, even though the MARS is actually the best?
An important detail about privacy methods is that whoever receives the private data must know the mechanism used to make the data private. Knowing this, you would probably avoid evaluating the RF and conclude that the MARS is the best approach.
While the utility of the private data versions through the use of the MSPE has been discussed as a measure for this, how risky these versions are (i.e., how much information is released about the original data?) has not been evaluated. In this sense, when using synthetic data methods, such as the CART approach in the previous example, there is no unique measure of how risky this version of the data is. On the other hand, differentially private mechanisms come with a parameter, commonly denoted as “ϵ” (epsilon), which provides a probabilistic measure of the risk associated with releasing the data.
The general rule for choosing this positive-valued parameter is that the closer to zero, the lower the risk (but the worse the utility). With ϵ = 1 for this example, the MSPE results are greatly affected by the differentially private mechanism applied to the data (third column). Since the goal of this mechanism is to make it hard to distinguish and identify the engines, how this can affect the MSPE can be seen. It is also difficult to identify a clear winner among the prediction methods. Indeed, based on these results, the RF could be discarded and which of the other three methods to recommend would not be clear.
In this case, while encouraging using any of the remaining three methods, Bob probably should choose the LR, since it has the best MSPE, along with the GLM, and is a simpler method. This would lead Bob to use the second-best method if considering the (true) original data.
Suppose that a method provides a prediction denoted as ŷ, then the MSPE is given by:
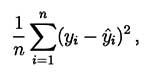
where n is the number of observations (rows) in the data and the index i refers to the ith observation. The MSPE is therefore the average value of the squared difference between the true remaining lifetime and the predicted one. The best method is consequently the one that minimizes this measure, implying that its predictions are closer to the true values.
A Private Roadmap
Privacy and statistical disclosure methods mainly focus on protecting the “identity” of rows in the data (e.g., individuals, vehicles, etc.) and are being employed in several governmental agencies. Therefore, as highlighted above, there are many data settings where the DoD can already make use of available privacy techniques to facilitate sharing their data. However, DoD data sets can often prove to be a different beast from the targets that statisticians are accustomed to exploring.
The DoD is typically concerned with protecting the capabilities and locations of their units and machinery as much as or more than their identities (justifying the scaling approach in the previous example, which may, however, not be enough). Given this, one potential roadmap for the DoD to follow starts with the adoption of existing privacy techniques in applicable data releases, while, in a second step, focusing on developing privacy techniques that address the unique challenges of DoD data.
As highlighted, the DoD is not interested in protecting only rows in the data but also the columns where the values may not necessarily provide information about the rows, but could reveal information about how or where those rows were measured (such as location). Moreover, “analysis-blind” synthetic methods should be better explored since, in many cases, the DoD wants to share data exactly to understand what kind of analysis can be performed without knowing it a priori.
All this must be considered in the light of the typical DoD formal guiding security documents, which lay out exactly what information can and cannot be revealed for each data set and piece of information.
Further Reading
Operational and scientific issues associated with adopting privacy methods:
Garfinkel, Simson L., Abowd, John M., and Powazek, Sarah. 2018. Issues encountered deploying differential privacy. Proceedings of the 2018 Workshop on Privacy in the Electronic Society.
Formal privacy methods:
Nissim, Kobbi, et al. 2017. Differential privacy: A primer for a non-technical audience. Privacy Law Scholars Conference.
U.S. Census Bureau’s disclosure avoidance practices and implementation of differential privacy in the 2020 Census:
Abowd, John. 2018. The U.S. Census Bureau Adopts Differential Privacy. SIGKDD Conference on Knowledge Discovery and Data Mining.
Disclosure Avoidance and the 2020 Census.2020. www.census.gov.
McKenna, Laura. 2019. Disclosure Avoidance Techniques Used for the 1960 Through 2010 Decennial Censuses of Population and Housing Public Use Microdata Samples. Washington, DC: United States Census Bureau (Working Paper).
About the Authors
Roberto Molinari is an assistant professor in the Department of Mathematics and Statistics at Auburn University. He received his PhD in statistics at the University of Geneva. His research focuses on robust statistics and stochastic processes, as well as model/feature selection and differential privacy. He has contributed to the development of online textbooks about data science and time series analysis with R and developed several R packages implementing his methodologies.
Michelle Pistner Nixon is a doctoral candidate in the Department of Statistics at the Pennsylvania State University (Penn State). Her research focus is statistical data privacy, and she is interested in applying data privacy methods to other domains, especially in the context of public policy and social good.
Steven Nixon is a research and development engineer in the Applied Research Laboratory at Penn State. His work is primarily in condition-based maintenance and machinery failure prediction. He has worked on the implementation of new sensor types for failure prediction and the use of data science to improve predictions based on existing data sources.








